Continuing from our discussion on Integrating Payment into your SaaS Web App, let’s delve into the realm of customized database design. Recognizing that data requirements vary across organizations, we introduce ‘custom fields’. These user-defined fields or custom columns offer the flexibility to capture and manage data based on each organization’s unique needs. In this article, we’ll explore various methods of storing these custom fields in your database.
Entity Attribute Value
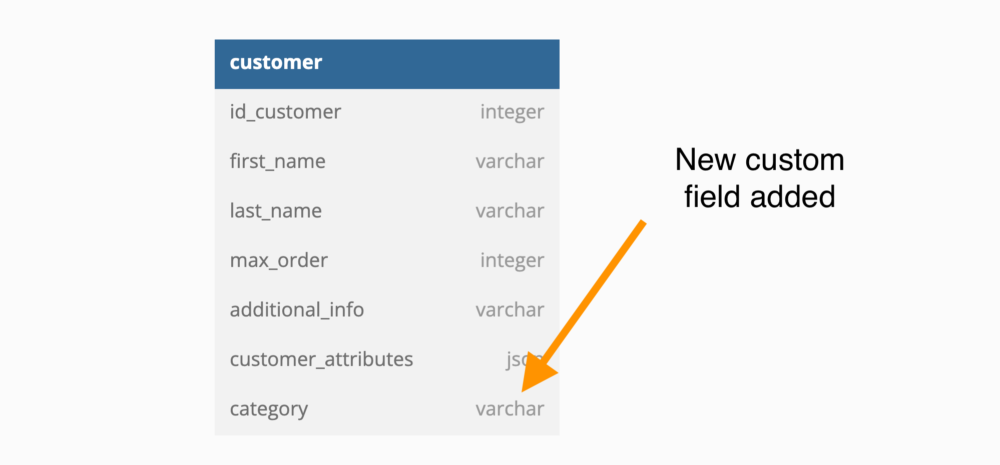
This is not a good design and should be avoided in most cases. It might look like a good and easy table but it has disadvantages. This method will perform poorly with lots of data, and you need to write queries that access the table in a specific way to slow down the queries. If you want to write queries, you will most likely need more complex subqueries. You also need help to validate data types quickly. Always avoid it if you can.
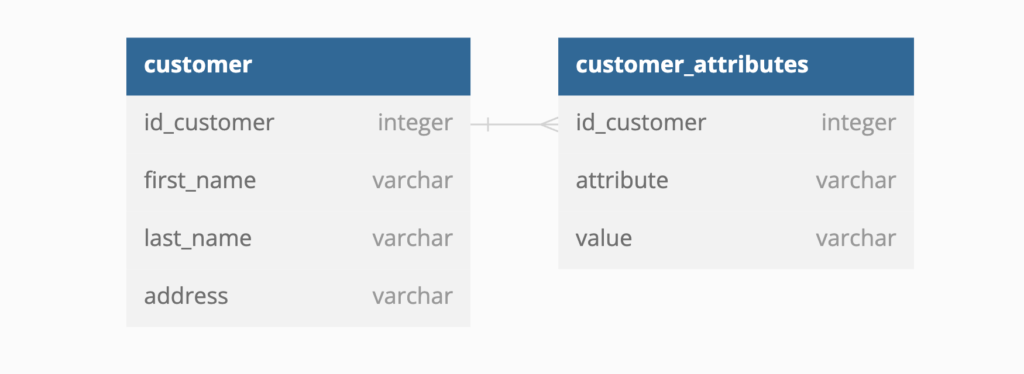
Modified Entity Attribute Value
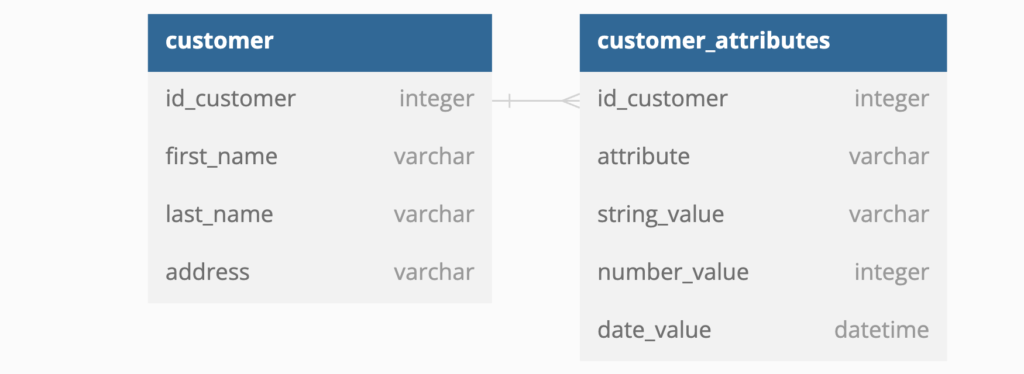
This follows the same design as the EAV table. The difference is that there are three columns instead of one value column. It makes enforcing data quality much easier, makes numbers can be sorted, and so on. Numbers are valid, and dates are valid no need to convert the values into proper types, it has the same flexibility but is more robust. Meaning on the user interface, they can select one string, number, or date and populate only one.
The disadvantages are that you risk multiple columns being updated and then poor performance. There is also poor performance, the same as the EAV, you will still need the subqueries, and the data validation will still be hard. Avoid this as much, but resort to this if you have no choice.
Single Table Inheritance

It’s called the Single Table Inheritance on Martin Fowler’s website. It involves adding all the columns you need to the main table, and you would need to think about all the data you need and add all the columns to that table. One advantage is that all the columns are in the same table, only select the columns you want and filter the ones you need. Only index the columns you need so the performance will be very good. No need for subqueries. You can add data validation like any other table column.
Disadvantages are that it will be extremely hard to work with lot’s of columns and it really isn’t flexible. It will also definitely be hard to convince people on your team to use this method. I prefer this but it depends on the data you want to store.
Class Table Inheritance
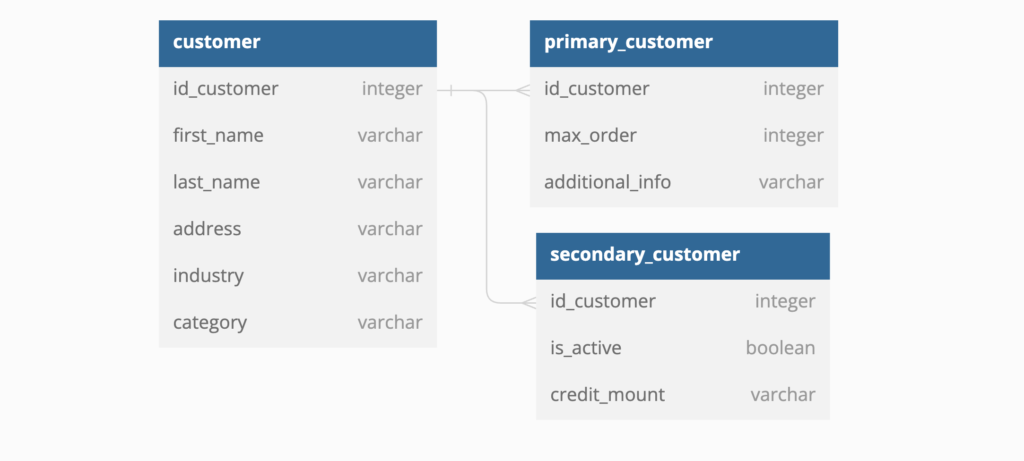
Same thing as the single table, with class table inheritance, each of the customer tables are linked to the main table, and you can perform your queries respectively. If you don’t like one big table, you can have multiple small tables and still enjoy improved data validation and improved performance.
The disadvantage is that it’s not very flexible since we still need the columns to exist so the customers can use them. Multiple tables will be sore to the eyes and confusing, thus being hard to maintain, and the queries will be much harder to understand.
Concrete Table Inheritance

Same thing with the previous two examples, this Concrete Table Inheritance example is also from Martin Fowler. It’s the same as the class inheritance with a twist: there is no main or master table. Each table has the data we need. Unlike the EAV designs, we can still validate our data with good performance and fewer joins since there is no central table.
The disadvantages are: It still needs to be more flexible in the number of columns customers can add. It also doesn’t allow the users to add the custom columns we need. You will also need the extra logic to handle different record types.
JSON

You can define a JSON field in your table, which can be used to store whatever data you want. It is flexible because the JSON field adheres to a JSON format. You can have as many or as few attributes as you want; they can all be different. The JSON field helper functions in most vendor databases have improved over time. You also only need one field instead of the complicated tables.
The disadvantages are that the data validation is hard to do as JSON fields are formatted strings. There can be functions to help add and read data, but it’s more difficult than other designs. You will also be restricted to using functions available in your database. JSON fields are prone to be messy, as there is no structure or rules around the data.
Dynamic Schema
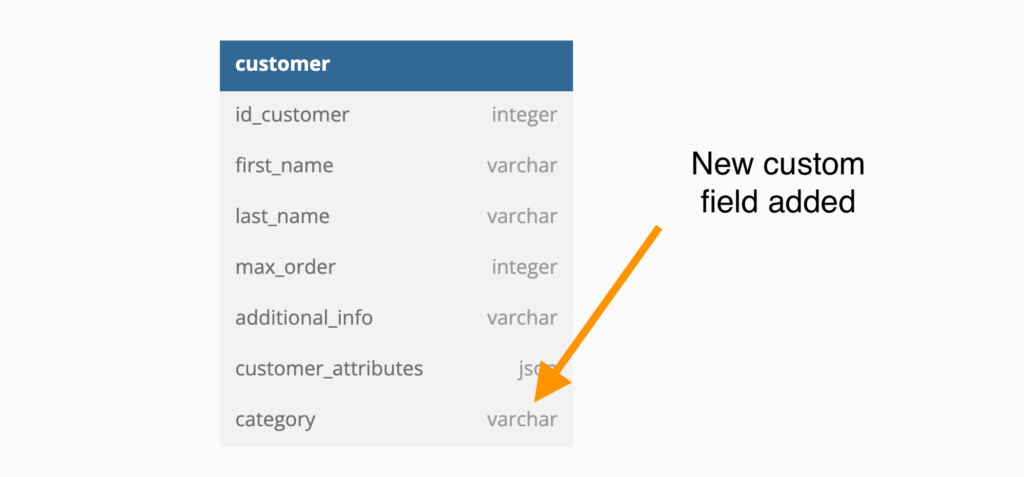
This is precisely what you think it is, dynamically running alter table statements to add new columns to the table as the customer wants it. This ensures the flexibility to add custom columns is there. The customer will provide a name, type, and value, and we will alter the table in real-time and add the column. Keeps the same pros as the above tables in terms of flexibility and performance.
As you might have guessed, modifying the database on a live system will be risky and might cause all sorts of issues, including data loss and unknown errors. You must ensure the field names adhere to the correct field_name length and content length.
You will need to find which one works great for your use cases, but if you made it this far, why? Just kidding, let me know which of these methods you are more likely to use.